Kaleidoscope: Semantically-grounded, Context-specific ML Model Evaluation
ACM Human Factors in Computing Systems (CHI), 2023 DOI

Harini Suresh
MIT CSAIL
Divya Shanmugam
MIT CSAIL

Tiffany Chen
MIT CSAIL

Annie Bryan
MIT CSAIL
Alexander D'Amour
Google Research
John V. Guttag
MIT CSAIL

Arvind Satyanarayan
MIT CSAIL
Abstract
Desired model behavior often differs across contexts (e.g., different geographies, communities, or institutions), but there is little infrastructure to facilitate context-specific evaluations key to deployment decisions and building trust. Here, we present Kaleidoscope, a system for evaluating models in terms of user-driven, domain-relevant concepts. Kaleidoscope’s iterative workflow enables generalizing from a few examples into a larger, diverse set representing an important concept. These example sets can be used to test model outputs or shifts in model behavior in semantically-meaningful ways. For instance, we might construct a “xenophobic comments” set and test that its examples are more likely to be flagged by a content moderation model than a “civil discussion” set. To evaluate Kaleidoscope, we compare it against template- and DSL-based grouping methods, and conduct a usability study with 13 Reddit users testing a content moderation model. We find that Kaleidoscope facilitates iterative, exploratory hypothesis testing across diverse, conceptually-meaningful example sets.
Bibtex
@inproceedings{2023-kaleidoscope,
title = {{Kaleidoscope: Semantically-grounded, Context-specific ML Model Evaluation}},
author = {Harini Suresh AND Divya Shanmugam AND Tiffany Chen AND Annie Bryan AND Alexander D'Amour AND John V. Guttag AND Arvind Satyanarayan},
booktitle = {ACM Human Factors in Computing Systems (CHI)},
year = {2023},
doi = {10.1145/3544548.3581482},
url = {https://vis.csail.mit.edu/pubs/kaleidoscope}
}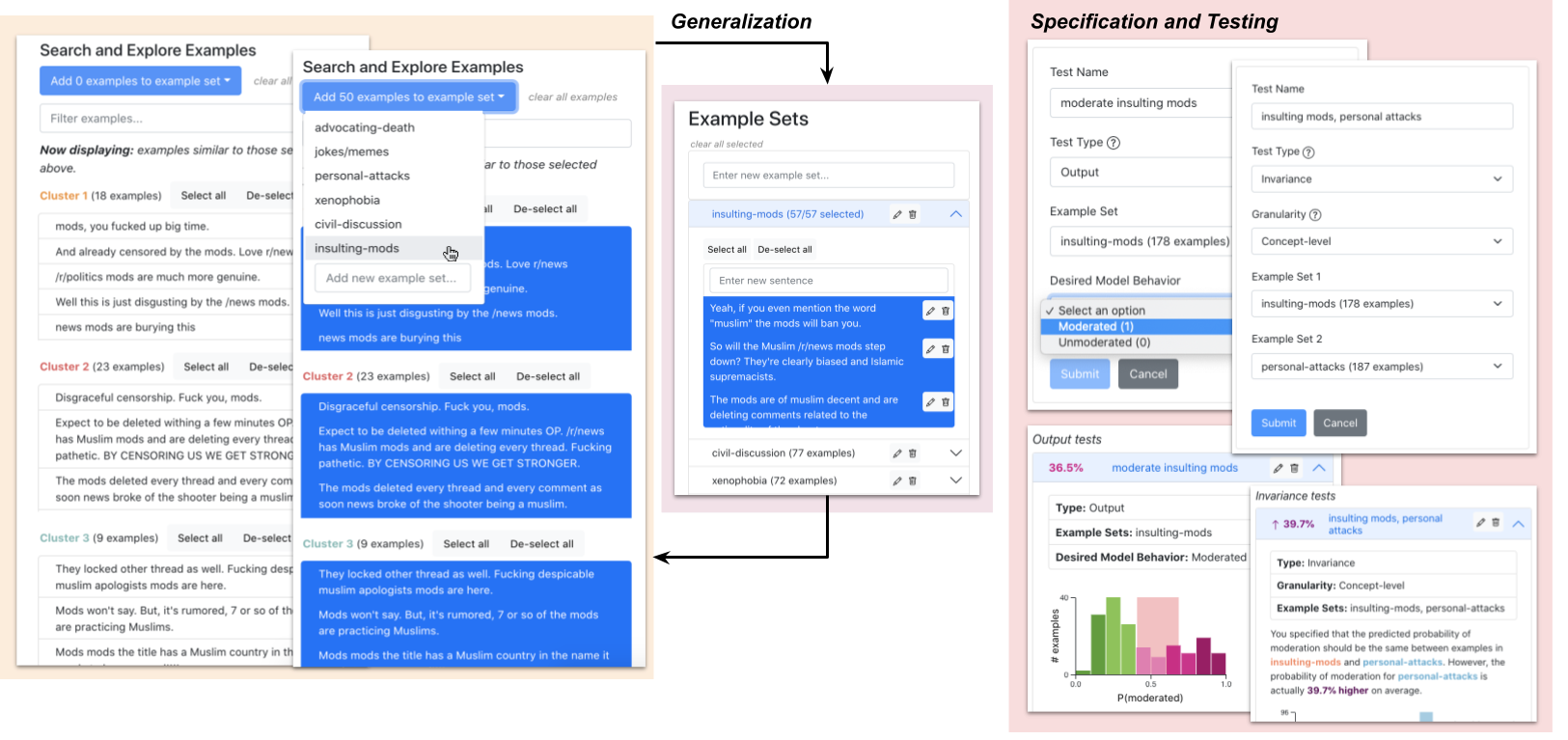
Kaleidoscope’s workflow consists of identifying meaningful examples, generalizing them into larger, diverse sets representing important concepts, and using these concepts to specify and test model behavior.