
VizNet: Towards A Large-Scale Visualization Learning and Benchmarking Repository
Kevin Hu MIT Media Lab
Snehalkumar "Neil" S. Gaikwad MIT Media Lab
Madelon Hulsebos MIT Media Lab
Michiel Bakker MIT Media Lab
Emanuel Zgraggen MIT CSAIL
César Hidalgo MIT Media Lab
Tim Kraska MIT CSAIL
Guoliang Li Tsinghua University

Çağatay Demiralp MIT CSAIL
ACM Human Factors in Computing Systems (CHI), 2019
Abstract
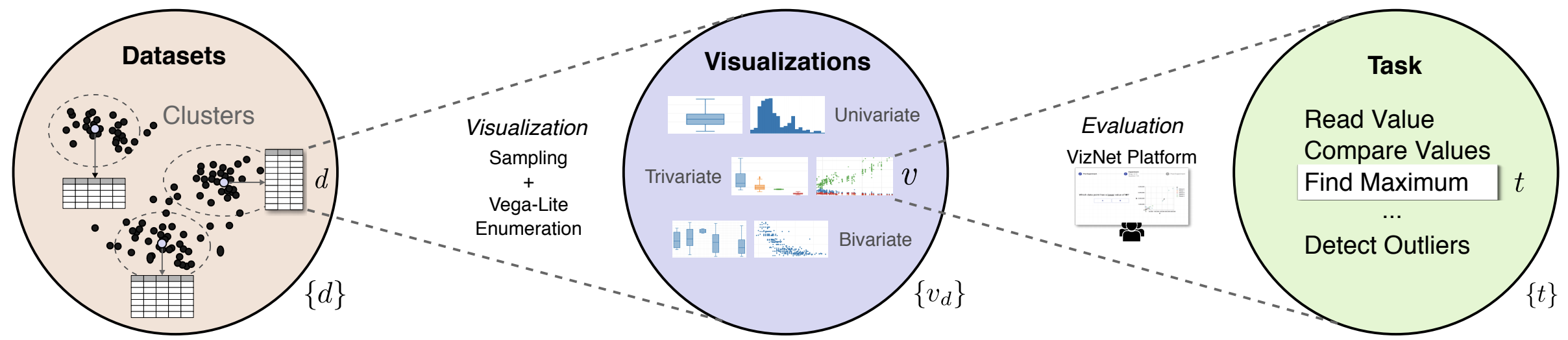
Researchers currently rely on ad hoc datasets to train automated visualization tools and evaluate the effectiveness of visualization designs. These exemplars often lack the characteristics of real-world datasets, and their one-off nature makes it difficult to compare different techniques. In this paper, we present VizNet: a large-scale corpus of over 31 million datasets compiled from open data repositories and online visualization galleries. On average, these datasets comprise 17 records over 3 dimensions and across the corpus, we find 51% of the dimensions record categorical data, 44% quantitative, and only 5% temporal. VizNet provides the necessary common baseline for comparing visualization design techniques, and developing benchmark models and algorithms for automating visual analysis. To demonstrate VizNet’s utility as a platform for conducting online crowdsourced experiments at scale, we replicate a prior study assessing the influence of user task and data distribution on visual encoding effectiveness, and extend it by considering an additional task: outlier detection. To contend with running such studies at scale, we demonstrate how a metric of perceptual effectiveness can be learned from experimental results, and show its predictive power across test datasets.